
Photo by Jan Genge on Unsplash
在開發應用程式的過程中,或多或少都有機會發生錯誤,原因可能是使用者輸入不正確的資料、網路斷線或語法上的問題等,而如果沒有做好例外處理的機制,程式碼可能因此中斷或發生不可預期的情況,況且讓客戶看到錯誤訊息,對產品的信心也會大打折扣。
為了避免上述的情形發生,在開發的過程中就應考慮到錯誤發生時,程式碼要如何做適當的反應,這也就是今天要跟大家分享的主題,讓程式碼在發生錯誤時,能夠顯示友善的錯誤訊息,並且程式碼不會因此而中斷。除了在開發上易於偵錯外,也避免產品上線時發生問題而顯示天文訊息給使用者看。Python在例外處理的機制,包含了:
- 基本的例外錯誤處理(try-except)
- 不同的例外錯誤處理(different
exceptions)
- finally區塊(try-except-finally)
- 自行拋出例外錯誤(raise exceptions)
一、基本的例外錯誤處理(try-except)
在學習Python基本的例外錯誤處理前,先來了解什麼是例外錯誤?如下範例:

像這樣沒有做好例外處理,除了程式碼中斷外,也讓使用者看到了這樣的天文訊息,如果又不幸的被駭客看到了,它可能就藉此知道哪行程式碼出現了漏洞。所以在開發應用程式時,例外處理非常的重要。Python基本的例外錯誤處理就是將程式碼置於try區塊中,接著在except區塊定義當try區塊中有任一行發生例外錯誤時,需進行什麼樣的反應或處理,如下範例:

進行try-except的例外處理後,程式碼沒有中斷,並且執行了我們所預期發生錯誤時,要進行的動作。相反的,當沒有例外發生時,except區塊中的程式碼則不會被執行。
如果在開發的過程中,大概知道可能會發生的例外錯誤類別,則可於except關鍵字之後加上該類別名稱,而發生此類別以外的錯誤,就會執行沒有加類別名稱的except區塊,如下範例:
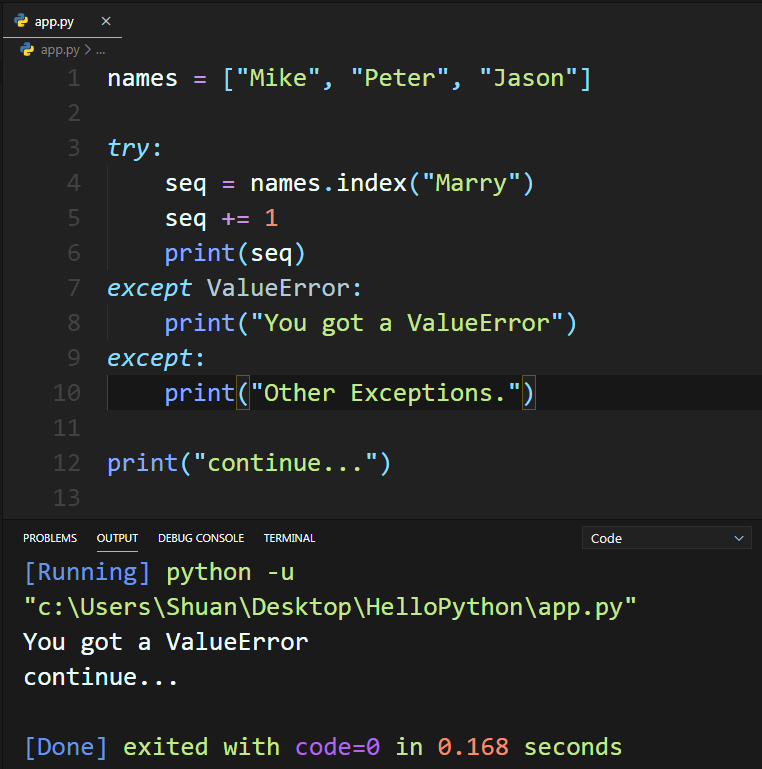
由於範例中發生了ValueError的錯誤,所以執行了ValueError的except區塊程式碼。
二、不同的例外錯誤處理(different
exceptions)
在try區塊中,如果發生一個種類以上的例外錯誤,則依序遞增except區塊,並於關鍵字之後加上例外錯誤的類別,如下範例:

這樣的寫法各例外錯誤類別有各自的例外處理動作。如果各例外錯誤類別有相同的處理動作,則可以在同一個except關鍵字之後於括號內加上各例外錯誤的類別,並以逗號區隔,只要try區塊中發生的例外錯誤類別有任一個配對到,即會執行該except區塊,如下範例:

範例中有一個重要的觀念,在例外錯誤發生進行except配對時,是由上而下,只要有except配對成功,剩下的except就算有配對到也不會執行,所以執行結果只有顯示一則except的訊息。
三、finally區塊(try-except-finally)
在實務上開發時,不論是資料庫的連線或是檔案處理,最後運算完成都要把資源釋放,否則資源將耗盡或無法開啟檔案,在一般情況下,我們都會把釋放資源的程式碼放在運算的最後,如下範例:
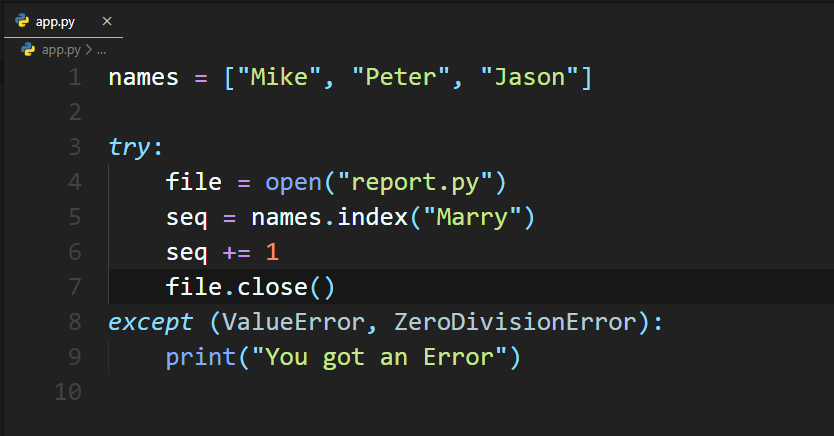
這樣的寫法當釋放資源的程式碼(第7行)之前發生例外錯誤時,控制權即會跳到except區塊,而沒有執行到釋放資源的程式碼。那如果置於except區塊呢?如下範例:

除非發生例外錯誤,否則也沒有釋放資源。那一定有人會說,加在except區塊及程式碼結尾,如下範例:

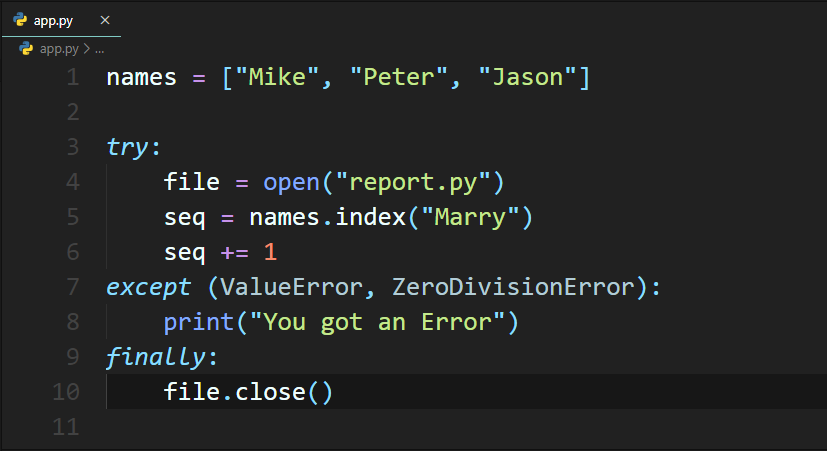
雖然可以達到不論是否有例外錯誤,都能夠釋放資源,不過同樣的程式碼重複出現在應用程式中是不好的,除了容易出現錯誤(Bug)外,也不易維護,所以正解就是在try-except的最後加上finally區塊,不論程式碼是否有發生例外,finally區塊都會被執行,非常適合釋放外部的資源,如下範例:
四、自行拋出例外錯誤(raise
exceptions)
舉例來說,在開發網站時,都會有機會讓使用者填寫表單,而表單資料送到伺服器端時,都會檢核資料是否正確,當有資料不正確時,就可以自行決定在什麼情況下要拋出什麼樣的例外錯誤。而Python拋出例外錯誤的語法為 raise關鍵字加上例外錯誤的類別,接著自訂錯誤訊息,如下範例:
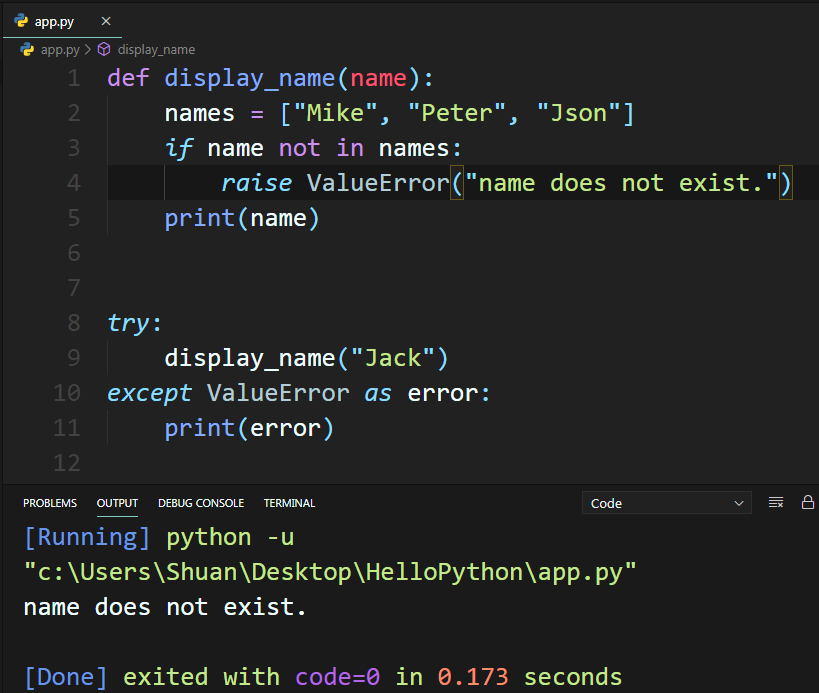
範例中需要注意的地方是,當自行拋出例外錯誤時,在呼叫端一定要作例外處理,才會顯示自訂之錯誤訊息。另外,為了讓程式碼簡潔,也可在例外錯誤類別之後利用 as 關鍵字,另取別名。
那我們要怎麼知道有哪些例外錯誤類別可以使用呢?可以至官方文件參考內建的例外錯誤類別。
五、小結
以上就是Python例外錯誤處理的介紹,檢視一下自己的程式碼是否有做好適當的錯誤處理機制吧。在練習的過程中若有碰到問題或說明不清楚的地方,歡迎留言與我分享!
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
有想要看的教學內容嗎?歡迎利用以下的Google表單讓我知道,將有機會成為教學文章,分享給大家😊




留言
張貼留言