
Photo by Kevin Bhagat on Unsplash
在實務上發展應用程式時,除了可以自行開發模組(Module)與套件(Package)外,很多時候會安裝使用第三方套件(Package),來提升專案的開發效率。
所以本文將介紹如何在PyPI中搜尋所需的Python套件(Package),並且以Windows作業系統及Visual Studio Code開發工具為例,瞭解Python強大的套件管理工具,讓您有效管理專案中的Python套件(Package)。
由於是在Visual Studio Code的Terminal視窗中下指令的方式來操作,所以使用命令提示字元視窗,也可以達到相同的效果。本文重點包含:
- PyPI(Python Package Index)
- pip套件管理工具
- pipenv套件管理工具
- Pipfile及Pipfile.lock檔案
一、PyPI(Python Package Index)
PyPI是一個套件庫,位於https://pypi.org,其中包含了各式各樣的Python套件(Package),在開發應用程式的過程中,可以到這邊來搜尋是否有所需的功能套件(Package),安裝後透過引用的方式來進行使用,藉此提升開發效率。
現在就來介紹幾個在使用PyPI時,需要瞭解的基本功能。首先,PyPI的首頁如下圖:
現在就來介紹幾個在使用PyPI時,需要瞭解的基本功能。首先,PyPI的首頁如下圖:

各位可以在搜尋的地方查詢所需的套件,例如搜尋常應用在網路爬蟲的beautifulsoup4套件(Package),從查詢結果可以看到許多相關的套件(Package),如下圖:

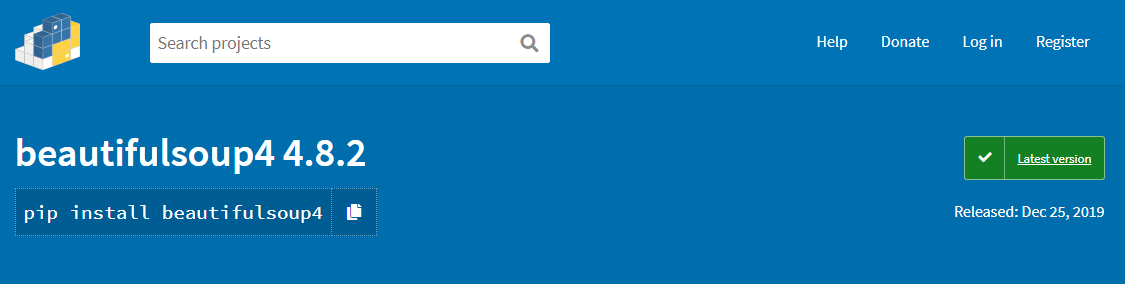
以beautifulsoup4 4.8.2為例,點進此套件(Package)後,可以看到安裝的指令及最新版的發佈日期,如下圖:
一個套件(Package)要如何使用,一定會有文件可以參考,往下即可看到Documentation的連結,如下圖:

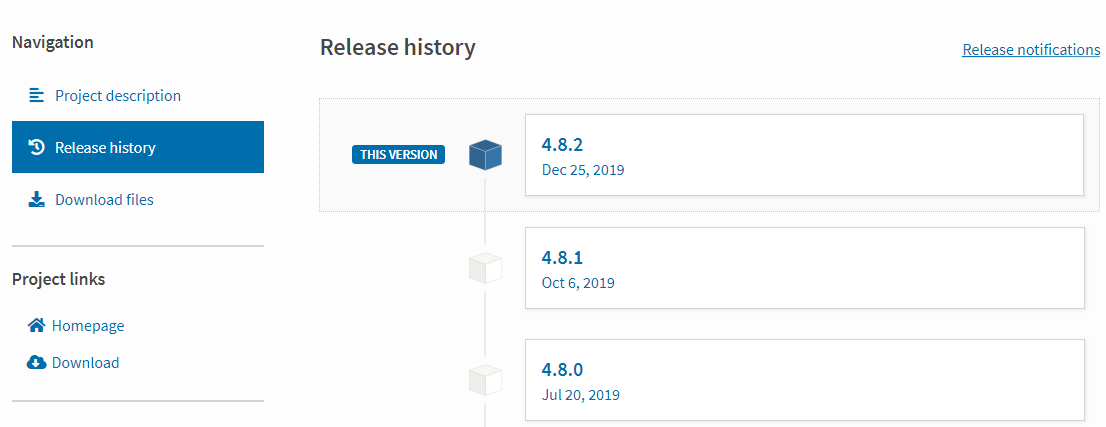
而套件(Package)的版本演進歷史則可以透過左邊的Release history來查看,如下圖:
以上是在使用PyPI上查找套件(Package)時,較常使用的部分,接下來,就來教大家如何透過指令來安裝套件(Package)吧。
二、pip套件管理工具
pip是一個全域環境的套件管理工具,用來安裝及管理PyPI上的Python套件(Package),也就是說利用pip指令所安裝的Python套件(Package),所有專案皆可使用。其中包含了幾個常用的操作方式,將以beautifulsoup4套件(Package)來進行示範。
- 安裝套件
使用pip install加上套件名稱,如下範例:

如果在執行安裝的指令後,出現以下的警告訊息:
代表pip有新的版本,需透過它最後所提供的指令進行升級後,再執行安裝的指令,如下範例:
pip升級完成並且執行pip install安裝指令後,將會安裝此套件(Package)的最新版本,以此範例來說,目前beautifulsoup4套件(Package)的最新版為4.8.2,如果想要安裝特定的版本4.8.0,則可加上 == 符號,特別注意 == 符號前後不能有空白,否則會出現錯誤訊息,如下範例:
同樣的,如果想要安裝版號為4開頭的最新版,也就是4.8.2,則可執行以下指令:
- 升級套件
使用pip install --upgrade加上套件名稱來進行升級,如下範例:
- 列出套件清單
使用pip list來檢視電腦中目前已安裝的套件及版本,如下範例:

- 移除套件
使用pip uninstall加上套件名稱來進行移除的動作,如下範例:
三、pipenv套件管理工具
利用pip套件管理工具所安裝的套件(Package),是在全域環境(Global)中,當今天有兩個專案需要beautifulsoup4不同的版本,這時候將無法達成,因為全域環境無法並存兩個相同的套件(Package)。
所以就可以使用整合了pip及虛擬環境的pipenv套件管理工具,為專案建立一個獨立的虛擬環境(Virtual Environment),並且將所需的套件(Package)安裝在裡面,這樣其中的套件(Package)就不會和全域環境及其他專案互相影響。
要使用pipenv套件管理工具,需利用pip來進行安裝,如下範例:
所以就可以使用整合了pip及虛擬環境的pipenv套件管理工具,為專案建立一個獨立的虛擬環境(Virtual Environment),並且將所需的套件(Package)安裝在裡面,這樣其中的套件(Package)就不會和全域環境及其他專案互相影響。
要使用pipenv套件管理工具,需利用pip來進行安裝,如下範例:
安裝完成後,即可透過pipenv套件管理工具來為專案建立虛擬環境及安裝套件(Package),如下範例:
範例中pipenv套件管理工具為專案建立一個虛擬環境,並且在裡面安裝beautifulsoup4套件(Package)。而這個虛擬環境在哪裡呢?可以利用pipenv --ven來查看,如下範例:

各位可以看到,虛擬環境並不在我們的專案中,這讓我們的專案容量,不會受到開發規模擴大時,隨著安裝的套件(Package)增多而越來越大。有了虛擬環境,接著即可透過pipenv shell進入,如下範例:
執行後會發現目錄的前方多顯示了虛擬環境的名稱,代表已成功進入,如下範例:

這邊要注意的地方是,由於pipenv套件管理工具在虛擬環境中安裝套件(Package),所以必須進入虛擬環境後再執行應用程式,否則其中所引用的套件(Package)將會找不到而發生錯誤。
另外,利用exit指令離開虛擬環境。這時候在目錄前面則不會顯示虛擬環境的名稱,如下範例:
另外,利用exit指令離開虛擬環境。這時候在目錄前面則不會顯示虛擬環境的名稱,如下範例:
四、Pipfile及Pipfile.lock檔案
當執行pipenv install指令安裝套件(Package)時,會發現專案中增加了兩個檔案,分別為Pipfile及Pipfile.lock,這兩個檔案負責管理專案的套件相依性及版本。首先,我們來看Pipfile的內容,如下圖:
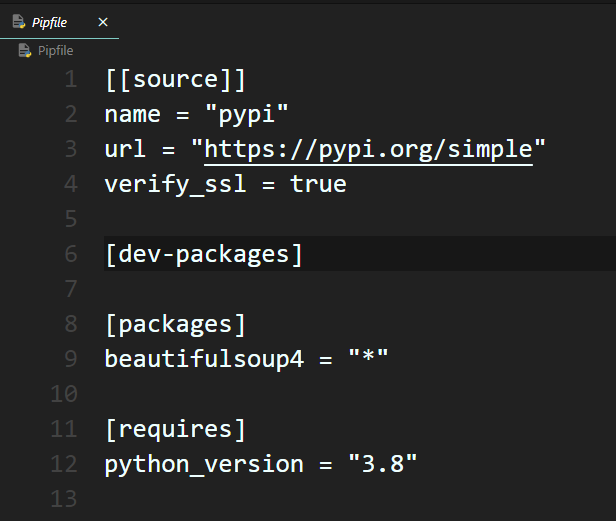
其中的source區塊指明了安裝套件的來源。dev-package區塊為測試環境所需的套件(Package)。而packages區塊包含了專案所安裝的套件(Package),可以看到beautifulsoup4套件等於 * 符號,代表最新的版本。最後requires區塊則是執行此專案所需的Python版本。
而Pipfile.lock是一個JSON格式的檔案,其中列出了各套件詳細的版本及相依性,如下圖:
而Pipfile.lock是一個JSON格式的檔案,其中列出了各套件詳細的版本及相依性,如下圖:

從圖中可以看到,beautifulsoup4 4.8.2套件(Package)的相依性套件有soupsieve 1.9.5,當在安裝beautifulsoup4套件時,Python會自動將其相依性套件一起安裝,並且記錄於Pipfile.lock檔案中。
有了Pipfile及Pipfile.lock檔案,就可以很容易的在不同的電腦中,快速建立一模一樣的開發環境。舉例來說,各位可以把剛才所建立的虛擬環境檔案(\.virtualenvs\HelloPython-B6krgkNh)刪除,來模擬另一台電腦中只有專案原始碼而沒有虛擬環境,這時候只要執行以下指令:
有了Pipfile及Pipfile.lock檔案,就可以很容易的在不同的電腦中,快速建立一模一樣的開發環境。舉例來說,各位可以把剛才所建立的虛擬環境檔案(\.virtualenvs\HelloPython-B6krgkNh)刪除,來模擬另一台電腦中只有專案原始碼而沒有虛擬環境,這時候只要執行以下指令:

無須指定任何套件名稱,pipenv套件管理工具即會自動依據專案中,Pipfile檔案的package區塊來安裝套件(Package)。
如果想要基於Pipfile.lock檔案,利用其中記錄的特定版本套件來安裝,則可以執行--ignore-pipfile指令:
如果想要基於Pipfile.lock檔案,利用其中記錄的特定版本套件來安裝,則可以執行--ignore-pipfile指令:

此指令即忽略Pipfile檔案,而依據Pipfile.lock檔案進行安裝。
五、小結
以上是在開發Python應用程式時,套件管理工具的使用方式及重要概念,熟悉以上的用法,將有助於快速且容易的管理套件相依性及建置開發環境。如果在練習的過程中,有碰到任何問題歡迎留言分享。
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。




喜歡你的 Python 教學文章...
回覆刪除但比較混亂, 如果可以有文章整理的次序就更好...如
入門教學 (一) (二) ...(五)
可以有次序看...事半功倍
您好:
刪除感謝您的建議,後續會考量在系列的教學文標題加上次序,謝謝 :)
Mike你好,我是以前想學Python但中途放棄許多次的學生
回覆刪除感謝你寫了這麼好懂的文章,彷彿讓我開竅般
希望你能繼續持續下去!幫助更多人