
Photo by Adolfo Félix on Unsplash
各位在使用多數網站填寫表單時,像是註冊資料,都有遇過填寫的資料不正確時,出現錯誤訊息,提醒使用者進行修改的情況,這就是所謂的表單驗證,用來防止使用者輸入不正確的資料,導致網站無法執行或收集到錯誤的資訊。
在使用Python的Django框架來開發網站表單時,預設會依據資料模型(Model)中,所定義的欄位類型及參數設定,執行基本的檢核,但是實務上,有一些欄位可能需要特殊的檢核邏輯,這時候,就可以使用本文所分享的技巧,來客製化自己的表單驗證機制。
Django常用的Form及ModelForm兩大表單類別,客製化表單欄位驗證的方式大同小異,所以本文將以ModelForm為例,進行實作的說明,而Form類別,留給各位來進行練習。本文的重點包含:
在使用Python的Django框架來開發網站表單時,預設會依據資料模型(Model)中,所定義的欄位類型及參數設定,執行基本的檢核,但是實務上,有一些欄位可能需要特殊的檢核邏輯,這時候,就可以使用本文所分享的技巧,來客製化自己的表單驗證機制。
Django常用的Form及ModelForm兩大表單類別,客製化表單欄位驗證的方式大同小異,所以本文將以ModelForm為例,進行實作的說明,而Form類別,留給各位來進行練習。本文的重點包含:
- 建立Django Model(資料模型)
- 建立Django ModelForm(資料模型表單)
- Django ModelForm預設表單檢核
- Django ModelForm客製化表單檢核
一、建立Django Model(資料模型)
首先,在Django應用程式(APP)下,在models.py檔案中,新增一個資料模型類別,如下範例:
from django.db import models
class Customer(models.Model):
name = models.CharField(max_length=30, blank=False, null=False)
email = models.EmailField(blank=False, null=False)
tel = models.IntegerField()
接著,執行以下的Django Migration(資料遷移)指令,將資料模型中所定義的欄位屬性,同步至資料庫中:
$ python manage.py makemigrations
$ python manage.py migrate
最後,將Django資料模型加入至Django Administration(管理員後台),並且客製化欄位顯示方式,以方便檢視資料的新增狀況,如下範例:
from django.contrib import admin
from .models import Customer
class CustomerAdmin(admin.ModelAdmin):
list_display = ('id', 'name', 'email', 'tel') # 顯示欄位
admin.site.register(Customer, CustomerAdmin) # 加入至Administration(管理員後台)
啟動本地端伺服器,連線至Django Administration(管理員後台),即可看到所建立的資料模型,如下:
$ python manage.py runserver

二、建立Django ModelForm(資料模型表單)
Django資料模型建置完成後,在應用程式(APP)下,新增forms.py檔案,利用資料模型的欄位屬性來建立表單,也就是Django ModelForm(資料模型表單),如下範例:
from django import forms
from .models import Customer
class CustomerModelForm(forms.ModelForm):
class Meta:
model = Customer
fields = '__all__'
widgets = {
'name': forms.TextInput(attrs={'class': 'form-control', 'style': 'width:50%;'}),
'email': forms.TextInput(attrs={'class': 'form-control', 'style': 'width:50%;'}),
'tel': forms.TextInput(attrs={'class': 'form-control', 'style': 'width:50%;'})
}
labels = {
'name': '姓名',
'email': '電子郵件',
'tel': '聯絡電話'
}
範例中客製化顯示Django ModelForm(資料模型表單)的觀念,可以參考[Django教學7]透過Django ModelForm快速開發CRUD應用程式教學文章。接下來,開啟views.py檔案,撰寫初始化表單,以及送出後的儲存邏輯,最後,將表單傳遞至Template(樣板)中,如下範例:
from django.shortcuts import render, redirect
from .forms import CustomerModelForm
def index(request):
form = CustomerModelForm()
if request.method == "POST":
form = CustomerModelForm(request.POST)
if form.is_valid():
form.save()
return redirect('/customers')
context = {
'form': form
}
return render(request, 'customers/index.html', context)
接著,在index.html,利用Django Template(樣板)語法,來顯示傳遞過來的Django ModelForm(資料模型表單),如下範例:
{% extends 'base.html' %} {% block content %} <h1>客戶基本資料</h1> <form action="" method="POST"> {% csrf_token %} {{ form.as_p }} <input class="btn btn-primary" type="submit" value="" /> </form> {% endblock %}
開啟Django應用程式(APP)下的urls.py,設定此樣板的路由網址,如下範例:
from django.urls import path
from . import views
urlpatterns = [
path('', views.index, name='Index')
]

三、Django ModelForm預設表單檢核
這時候在沒有填寫任何資料的情況下,點擊儲存時,Django就會依據CustomerModelForm表單類別中,對應的資料模型所定義的屬性欄位及參數,進行基本的檢核,如下範例:
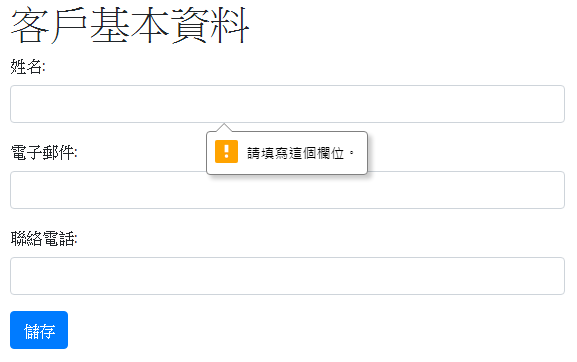
由於定義姓名及電子郵件的欄位不得為空,所以Django會進行表單檢核,要求填寫欄位資料。
四、Django ModelForm客製化檢核
雖然Django預設會幫我們進行表單資料的基本檢核,但是實務上,有時候需要特殊的邏輯來驗證資料,比如說,客戶在電子郵件的欄位,不得輸入Hotmail的電子郵件,該如何實現呢?這時候,就可以開啟Django應用程式(APP)下的forms.py檔案,在表單類別中,定義「clean_」關鍵字開頭的方法,並且加上欄位的名稱,在其中即可自訂該欄位的檢核邏輯,如下範例:
from django import forms
from .models import Customer
class CustomerModelForm(forms.ModelForm):
class Meta:
model = Customer
fields = '__all__'
widgets = {
'name': forms.TextInput(attrs={'class': 'form-control', 'style': 'width:50%;'}),
'email': forms.TextInput(attrs={'class': 'form-control', 'style': 'width:50%;'}),
'tel': forms.TextInput(attrs={'class': 'form-control', 'style': 'width:50%;'})
}
labels = {
'name': '姓名',
'email': '電子郵件',
'tel': '聯絡電話'
}
def clean_email(self, *args, **kwargs):
email = self.cleaned_data.get('email') #取得樣板所填寫的資料
if email.endswith('@hotmail.com'):
raise forms.ValidationError('不得使用Hotmail電子郵件')
return email
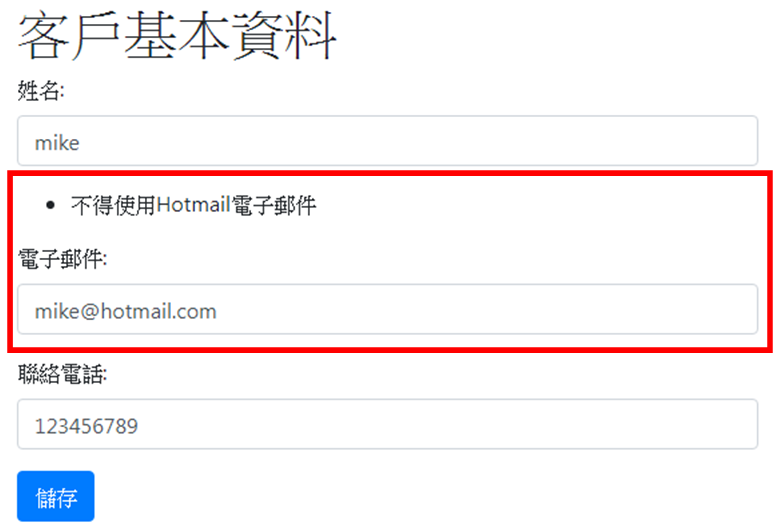
從執行結果可以看到,當輸入Hotmail的電子郵件時,則會依照自訂的檢核邏輯,顯示相應的錯誤訊息。而如果輸入非Hotmail的電子郵件,即可成功儲存至資料庫中,如下範例:

Django Administration(管理員後台)的儲存結果,如下圖:

五、小結
以上就是Django客製化表單檢核邏輯的方式,簡單來說,就是在Django的表單類別中,定義欄位的方法,在其中實作該欄位的檢核邏輯,讓網站的表單檢核更有彈性。詳細的實作歷程,可以參考GitHub原始碼,如果在練習的過程中,有碰到任何問題,歡迎大家留言提問或分享,我將盡力為各位解答,希望有幫助到大家。
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
GitHub網址:https://github.com/mikeku1116/django-formvalidation
- Python學習資源整理
- [Django教學1]3步驟快速安裝Django網站框架
- [Django教學2]建立Django應用程式(APP)
- [Django教學3]Django Migration(資料遷移)的重要觀念
- [Django教學4]實用的Django Administration操作及客製化技巧
- [Django教學5]Django Template(樣板)開發快速上手
- [Django教學6]Django Template(樣板)整合Bootstrap實戰教學
- [Django教學7]透過Django ModelForm快速開發CRUD應用程式教學
- [Python物件導向]解析Python物件導向設計的3種類型方法(Instance,Class,Static Method)
- 5個必知的Python Function觀念整理




工作需要,簡單易懂實用!
回覆刪除