
Photo by Nathana Rebouças on Unsplash
在數據爆炸的時代裡,許多的網站、社群平台及資訊系統等,擁有了大量的資料,為了要精準的找到符合所需的資料來進行分析、處理或存檔,這時候就非常需要仰賴查詢的功能,提供適當的條件來讓使用者進行資料篩選。
使用Python的Django框架來進行網站開發,想要提供這種多條件的查詢功能,則可以使用django-filter套件,它是一個能夠基於資料模型的欄位,動態依照條件來進行資料集的篩選,除了能夠簡化在檢視函式(View Function)中撰寫大量的查詢語法,也提升了開發效率。
所以本文將利用django-filter套件,來建置多條件的電影查詢功能,來示範它的使用方式。其中的實作包含:
- 安裝django-filter
- 建立資料模型(Models)
- 建立過濾器(Filters)
- 建立檢視函式(Views)
- 建立樣板(Templates)
- 客製化過濾器
一、安裝django-filter
首先,利用以下的指令來安裝django-filter:
$ pip install django-filter
安裝成功後,開啟Django專案中的settings.py檔案,在INSTALL_APPS的地方,加入django-filters,如下範例:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'movies.apps.MoviesConfig',
'django_filters',
]
二、建立資料模型(Models)
本文所使用的資料模型,如下範例:
from django.db import models
class Movie(models.Model):
GENRE_CHOICES = (
('action', '動作片'),
('romance', '愛情片'),
('drama', '劇情片'),
)
title = models.CharField(max_length=100) # 電影名稱
genre = models.CharField(max_length=20, choices=GENRE_CHOICES) # 電影類型
release_year = models.IntegerField() # 年份
分別包含了電影名稱、類型及上映年份,其中電影類型的選項(GENRE_CHOICES),前方為下拉選單存進資料庫中的值(value),而後方為顯示的文字(text)。
接下來,利用以下指令執行Django Migrations(資料遷移):
$ python manage.py makemigrations
$ python manage.py migrate
資料模型同步完成後,開啟Django專案的admin.py,將此資料模型加入至Django Administration(管理員後台),如下範例:
from django.contrib import admin
from .models import Movie
class MovieAdmin(admin.ModelAdmin):
list_display = ('title', 'genre', 'release_year')
admin.site.register(Movie, MovieAdmin)接著,利用以下指令建立Django Administration(管理員後台)的帳號密碼:
$ python manage.py createsuperuser
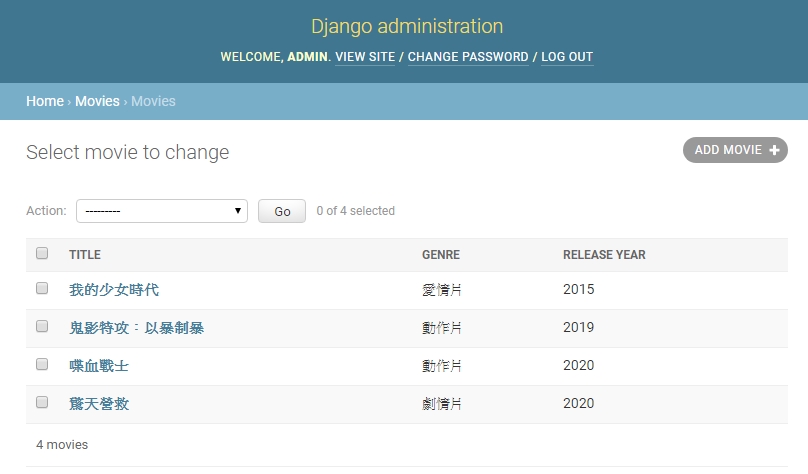
這時候,就可以啟動本地端伺服器,登入Django Administration(管理員後台),在剛剛所建立的Movie資料模型中,新增幾部電影資料,方便等一下進行多條件的查詢測試,如下圖:
三、建立過濾器(Filters)
Django資料模型的部分建置完成,在應用程式(APP)的資料夾下新增filters.py檔案,用來建置查詢資料的django-filter過濾器,如下範例:
from .models import Movie
import django_filters
class MovieFilter(django_filters.FilterSet):
class Meta:
model = Movie
fields = '__all__'範例中,引用所要查詢的資料模型及django-filters,接著,自訂過濾器類別(MovieFilter),並且繼承自FilterSet類別,其中,再利用model及fields屬性來分別指定所要查詢的資料模型和欄位。
四、建立檢視函式(Views)
django-filter建立完成後,開啟Django專案中的views.py檔案,撰寫以下的程式碼:
from django.shortcuts import render
from .models import Movie
from .filters import MovieFilter
def index(request):
movies = Movie.objects.all()
movieFilter = MovieFilter(queryset=movies)
if request.method == "POST":
movieFilter = MovieFilter(request.POST, queryset=movies)
context = {
'movieFilter': movieFilter
}
return render(request, 'movies/index.html', context)在範例的檢視函式(View Function)中,當第一次載入網頁時,由於請求方法為GET,所以在第9行利用queryset關鍵字參數(Keyword Argument),來指定django-filter物件所要查詢資料集,這邊需指定資料模型中的所有資料。
而當請求方法為POST,也就是使用者輸入查詢條件,按下查詢按鈕時,django-filter物件將依據請求所傳入的查詢條件(request.POST),來自動篩選資料集。
五、建立樣板(Templates)
接著,建立剛剛所指定的index.html樣板,其中包含上方的查詢條件表單及下方的查詢結果,如下範例:
{% extends 'base.html' %}
{% block content %}
<form method='POST'>
{% csrf_token %}
名稱:{{ movieFilter.form.title }}
類型:{{ movieFilter.form.genre }}
年份:{{ movieFilter.form.release_year }}
<input type="submit" class="btn btn-primary" value="查詢" />
</form>
<br />
<table class="table">
<thead>
<th>名稱</th>
<th>類型</th>
<th>年份</th>
</thead>
<tbody>
{% for movie in movieFilter.qs %}
<tr>
<td>{{ movie.title }}</td>
<td>{{ movie.get_genre_display }}</td>
<td>{{ movie.release_year }}</td>
</tr>
{% endfor %}
</tbody>
</table>
{% endblock %}執行結果
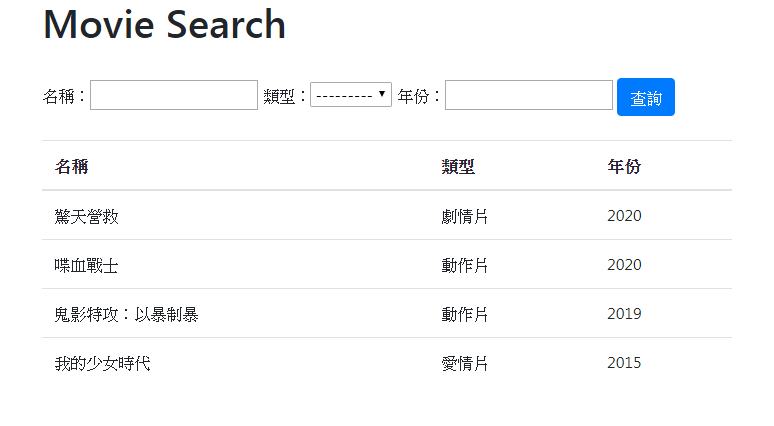
在上方查詢條件表單的部分,可以透過django-filter物件來建立,非常的方便。而下方的查詢結果,在透過迴圈讀取django-filter的資料時,需加上「.qs」,就是queryset資料集的意思。
這邊針對下方查詢結果的「類型」欄位來特別說明一下,由於在資料庫中是儲存類型的值(value),也就是"action"、"romance"及"drama",而當Django讀取出來要進行顯示時,則需使用像第23行的get_<欄位名稱>_display方式,來顯示相應的文字(text)。
六、客製化過濾器
到這邊事實上已經完成了Django多條件查詢的功能,但是各位可能還有兩個疑問:
- 目前所執行的查詢必須都要條件完全符合才查得到,如果「電影名稱」想要進行模糊查詢,該如何實作?
- 查詢條件的表單該如何套用Bootstrap樣式來進行美化?
這時候,就可以開啟Django專案中所建立的filters.py,來進行客製化,如下範例:
from django import forms
from .models import Movie
import django_filters
class MovieFilter(django_filters.FilterSet):
title = django_filters.CharFilter(
lookup_expr='icontains',
widget=forms.TextInput(attrs={'class': 'form-control'}))
genre = django_filters.CharFilter(
widget=forms.Select(choices=(('', '請選擇'),) + Movie.GENRE_CHOICES, attrs={'class': 'form-control'}))
release_year = django_filters.CharFilter(
widget=forms.NumberInput(attrs={'class': 'form-control'}))
class Meta:
model = Movie
fields = '__all__'執行結果
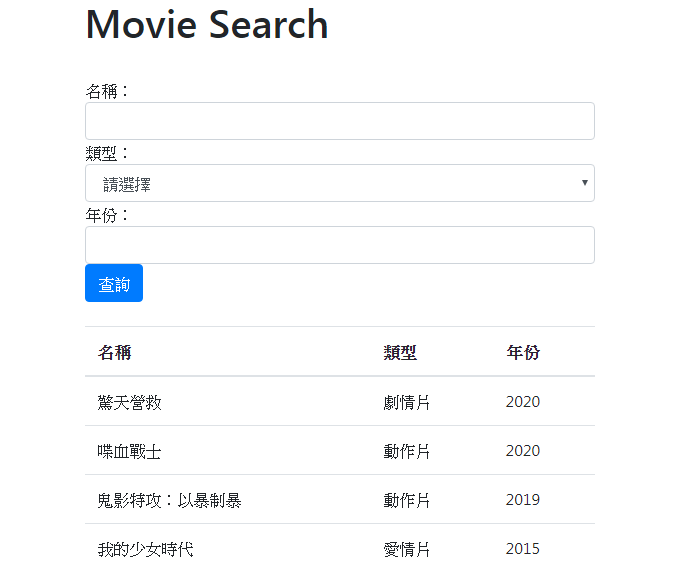
首先,「電影名稱」欄位想要進行模糊查詢,則可以像第9行一樣,指定django-filter的lookup_expr(查詢表示式)為「icontains」,當然,可想而知預設為「iexact」,也就是完全符合的意思。
另外,查詢條件的表單想要套用Bootstrap框架的樣式,就需要先引用Django的forms物件,之後則可以仿照建置Django Forms一樣,利用widget參數來套用CSS樣式。
七、小結
以上就是利用django-filter套件,來快速建構多個條件的查詢功能,除了提升開發效率外,使用的方式和Django ModelForm(資料模型表單)大同小異,很好上手,相較於傳統的方式來進行開發,簡化了檢視函式(View Function)中撰寫複雜的查詢語法及判斷式。詳細的實作程式碼,可以參考下方的GitHub網址唷。
有想要看的教學內容嗎?歡迎利用以下的Google表單讓我知道,將有機會成為教學文章,分享給大家😊




謝謝前輩 我會運用努力來支持您的苦心,謝謝對後輩學習者的貢獻,有時候卡很久卻沒有相對回報有點難過,謝謝您教學。
回覆刪除