Scrapy網頁爬蟲框架除了提供[Scrapy教學4]掌握Scrapy框架重要的CSS定位元素方法文章中所分享的css()方法(Method)來定位網頁元素(Element)外,也提供了xpath()定位方法(Method)讓開發者使用。
XPath(XML Path Language)是一個使用類似檔案路徑的語法,來定位XML文件中特定節點(node)的語言,因為能夠有效的尋找節點(node)位置,所以也被廣泛的使用在Python網頁爬蟲的元素(Element)定位上。
本文就延續使用[Scrapy教學4]掌握Scrapy框架重要的CSS定位元素方法文章中的INSIDE硬塞的網路趨勢觀察網站-AI新聞,來帶大家來認識如何在Scrapy框架中,使用內建的xpath()方法(Method)來定位想要爬取的網頁內容。重點包含:
- Scrapy XPath方法取得單一元素值
- Scrapy XPath方法取得多個元素值
- Scrapy XPath方法取得子元素值
- Scrapy XPath方法取得元素屬性值
一、Scrapy XPath方法取得單一元素值
首先,開啟INSIDE硬塞的網路趨勢觀察網站-AI新聞網頁,在文章標題的地方按滑鼠右鍵,選擇「檢查」,可以看到如下圖的HTML原始碼:
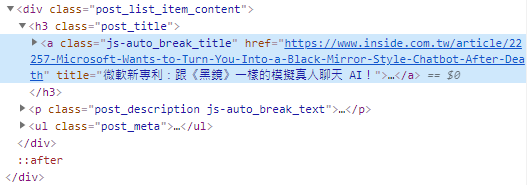
//a[@class='js-auto_break_title']
意思就像是根目錄下的<a>標籤,並且利用「[@class='']」來指定它的樣式類別(class),如此就能夠定位到文章標題的<a>標籤。
接下來,開啟[Scrapy教學4]掌握Scrapy框架重要的CSS定位元素方法文章所建置的Scrapy網頁爬蟲專案,在spiders / inside.py的parse()方法(Method)中,將網頁回應的結果(response),改為呼叫xpath()方法(Method),並且,貼上剛剛所得知的XPath路徑,如下範例:
import scrapy
class InsideSpider(scrapy.Spider):
name = 'inside'
allowed_domains = ['www.inside.com.tw']
start_urls = ['https://www.inside.com.tw/tag/ai']
def parse(self, response):
title = response.xpath(
"//a[@class='js-auto_break_title']/text()").get()
print(title)接著,利用以下指令執行inside網頁爬蟲:
$ scrapy crawl inside
執行結果
微軟新專利:跟《黑鏡》一樣的模擬真人聊天 AI!
以上範例的第11行,利用XPath路徑定位到所要爬取的<a>標籤後,由於要取得其中的網頁內容文字,所以在XPath路徑的最後需加上「/text()」關鍵字,並且,呼叫get()方法(Method)取得單一元素值。
二、Scrapy XPath方法取得多個元素值
如果想要利用Scrapy xpath()方法(Method)取得多個元素值,使用XPath路徑定位到所要爬取的網頁元素<a>標籤後,呼叫getall()方法(Method)即可,如下範例:
import scrapy
class InsideSpider(scrapy.Spider):
name = 'inside'
allowed_domains = ['www.inside.com.tw']
start_urls = ['https://www.inside.com.tw/tag/ai']
def parse(self, response):
titles = response.xpath(
"//a[@class='js-auto_break_title']/text()").getall()
print(titles)執行結果
[ '微軟新專利:跟《黑鏡》一樣的模擬真人聊天 AI!', '【Arm 專欄】一次看懂人工智慧:雲端、邊緣與終端人工智慧', '2021 台北電玩展以新形態亮相:虛實同步展出', '用科技保護環境!AI 可偵測亞馬遜雨林生態中非法道路的增減', '烘焙王!Google AI 未烤先猜你的配方會變甚麼食物,更創造混種甜點「breakie」、「cakie」', '她用數據戰勝人性,主推付費課程一年後用戶翻七倍', '【Wired硬塞】你知道銀河系的歷史,已被重新改寫了嗎?', '祖克柏放棄新年願望!2020 過的好嗎?盤點臉書滿城風雨的一年', ... ]
從執行結果可以看到,getall()方法(Method)會回傳一個串列(List),包含所有樣式類別(class)為「js-auto_break_title」的<a>標籤標題文字,接下來,就需要透過迴圈來進行讀取,如下範例:
import scrapy
class InsideSpider(scrapy.Spider):
name = 'inside'
allowed_domains = ['www.inside.com.tw']
start_urls = ['https://www.inside.com.tw/tag/ai']
def parse(self, response):
titles = response.xpath(
"//a[@class='js-auto_break_title']/text()").getall()
for title in titles:
print(title)執行結果
微軟新專利:跟《黑鏡》一樣的模擬真人聊天 AI! 【Arm 專欄】一次看懂人工智慧:雲端、邊緣與終端人工智慧 2021 台北電玩展以新形態亮相:虛實同步展出 用科技保護環境!AI 可偵測亞馬遜雨林生態中非法道路的增減 烘焙王!Google AI 未烤先猜你的配方會變甚麼食物,更創造混種甜點「breakie」、「cakie」 她用數據戰勝人性,主推付費課程一年後用戶翻七倍 【Wired硬塞】你知道銀河系的歷史,已被重新改寫了嗎? 祖克柏放棄新年願望!2020 過的好嗎?盤點臉書滿城風雨的一年 ...
本文使用的get()及getall()方法(Method),和[Scrapy教學4]掌握Scrapy框架重要的CSS定位元素方法文章一樣為Scrapy官方的新版使用方式,而舊版的extract_first()及extract()方法(Method),依據以下的官方文件說明,依然支援,不過還是建議讀者可以使用新版的方法(Method),較為簡潔與可讀性。

三、Scrapy XPath方法取得子元素值
在開發Python網頁爬蟲時,有很常的機率會需要透過逐層的方式,往下定位所要爬取的子元素(Element),這時候Scrapy xpath()方法(Method)中,所傳入的XPath路徑則跟檔案目錄一樣,一層一層的往下串接。以<a>標籤的HTML原始碼為例,如下圖:

import scrapy
class InsideSpider(scrapy.Spider):
name = 'inside'
allowed_domains = ['www.inside.com.tw']
start_urls = ['https://www.inside.com.tw/tag/ai']
def parse(self, response):
titles = response.xpath(
"//div[@class='post_list_item_content']/h3[@class='post_title']/a/text()").getall()
for title in titles:
print(title)執行結果
微軟新專利:跟《黑鏡》一樣的模擬真人聊天 AI! 【Arm 專欄】一次看懂人工智慧:雲端、邊緣與終端人工智慧 2021 台北電玩展以新形態亮相:虛實同步展出 用科技保護環境!AI 可偵測亞馬遜雨林生態中非法道路的增減 烘焙王!Google AI 未烤先猜你的配方會變甚麼食物,更創造混種甜點「breakie」、「cakie」 她用數據戰勝人性,主推付費課程一年後用戶翻七倍 【Wired硬塞】你知道銀河系的歷史,已被重新改寫了嗎? 祖克柏放棄新年願望!2020 過的好嗎?盤點臉書滿城風雨的一年 ...
四、Scrapy XPath方法取得元素屬性值
Python網頁爬蟲除了能夠爬取網頁上顯示的內容外,也可以取得網頁元素(Element)的屬性值,舉例來說,像是<img>圖片的src來源屬性值或<a>超連結的href網址屬性值等,這時候,就需要在Scrapy框架的xpath()方法(Method)最後,加上「@屬性名稱」,如下範例:
import scrapy
class InsideSpider(scrapy.Spider):
name = 'inside'
allowed_domains = ['www.inside.com.tw']
start_urls = ['https://www.inside.com.tw/tag/ai']
def parse(self, response):
titles = response.xpath(
"//a[@class='js-auto_break_title']/@href").getall()
for title in titles:
print(title)
執行結果
https://www.inside.com.tw/article/22257-Microsoft-Wants-to-Turn-You-Into-a-Black-Mirror-Style-Chatbot-After-Death https://www.inside.com.tw/article/22234-arm-AI-explained https://www.inside.com.tw/article/22254-2021-TGS https://www.inside.com.tw/article/22208-artificial-intelligence-finds-hidden-roads-threatening-amazon-ecosystems https://www.inside.com.tw/article/22196-google-ai-concocts-breakie-and-cakie-hybrid-baked-goods https://www.inside.com.tw/article/22222-sofasoda-growth-in-tech-2021 https://www.inside.com.tw/article/22194-The-Milky-Way-Gets-a-New-Origin-Story https://www.inside.com.tw/article/22057-Mark-Zuckerberg-and-fb-2020 ...
以上範例,即是爬取所有樣式類別(class)為「js-auto_break_title」的<a>標籤href屬性值,也就是文章標題的網址。
五、小結
本文簡單示範了Scrapy框架的另一個定位元素方法XPath,很明顯的可以感受到語法和檔案路徑非常相似,使用上也很直覺,重點摘要如下:
- 取得單一元素值呼叫get()方法(Method)
- 取得多個元素值呼叫getall()方法(Method)
- 取得文字內容,加上「/text()」關鍵字
- 取得屬性值則加上「@屬性名稱」關鍵字
大家可以試著練習利用本文所分享的Scrapy xpath()方法(Method),以及[Scrapy教學4]掌握Scrapy框架重要的CSS定位元素方法文章的css()方法(Method),來爬取想要的網頁內容,相信對於想要入門Scrapy框架來開發Python網頁爬蟲的朋友,能夠快速上手。
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。




我試著把"//div[@class='post_list_item_content']/h3[@class='post_title']/a/text()").getall()刪改為"//div/h3[@class='post_title']/a/text()").getall(),似乎也能正常運作。
回覆刪除