
想要進行資料分析,除了利用Python網頁爬蟲蒐集第一層的網頁資料外,有時候為了要更瞭解資料的內容或是讓分析的結果更加精確,就會需要爬取下一層的網頁,也就是詳細資料。
舉例來說,筆者想要對不同廠牌的筆電進行分析,這時候使用Python網頁爬蟲除了取得網頁第一層的筆電名稱外,還需要爬取每個筆電的下一層網頁,來取得詳細的規格內容,才有辦法進行比較。
本文將延續[Scrapy教學9]一定要懂的Scrapy框架結合Gmail寄送爬取資料附件秘訣文章的Scrapy專案,以INSIDE硬塞的網路趨勢觀察網站首頁的熱門文章為例,來和大家分享如何在Scrapy框架中爬取下一層的網頁內容。實作的步驟如下:
- Scrapy框架建立網頁爬蟲
- Scrapy網頁爬蟲爬取下一層網頁內容
- Scrapy框架建立資料模型封裝資料
一、Scrapy框架建立網頁爬蟲
首先,前往INSIDE硬塞的網路趨勢觀察網站,可以看到熱門文章如下圖:

這時候想要蒐集紅框中的五篇熱門文章摘要,就需要分別前往下一層網頁的連結來進行爬取。在熱門文章標題的地方點擊滑鼠右鍵,選擇「檢查」,可以看到HTML原始碼如下圖:

$ scrapy genspider hot_news www.inside.com.tw
這時候Scrapy專案的spiders資料夾下就會多了一個Scrapy網頁爬蟲(hot_news),如下圖:
二、Scrapy網頁爬蟲爬取下一層網頁內容
開啟Scrapy網頁爬蟲檔案(hot_news.py),可以看到如下範例:
import scrapy
class HotNewsSpider(scrapy.Spider):
name = 'hot_news'
allowed_domains = ['www.inside.com.tw']
start_urls = ['http://www.inside.com.tw/']
def parse(self, response):
pass接下來,在parse()方法(Method)的地方,透過Scrapy框架的xpath()方法(Method),來爬取INSIDE硬塞的網路趨勢觀察網站的所有熱門文章下一層網頁網址,如下範例:
import scrapy
class HotNewsSpider(scrapy.Spider):
name = 'hot_news'
allowed_domains = ['www.inside.com.tw']
start_urls = ['http://www.inside.com.tw/']
def parse(self, response):
post_urls = response.xpath(
"//a[@class='hero_menu_link']/@href").getall()詳細的Scrapy xpath定位元素方法教學可以參考[Scrapy教學5]掌握Scrapy框架重要的XPath定位元素方法文章。取得了所有熱門文章的下一層網頁網址後,就可以透過迴圈來進行請求,如下範例:
import scrapy
class HotNewsSpider(scrapy.Spider):
name = 'hot_news'
allowed_domains = ['www.inside.com.tw']
start_urls = ['http://www.inside.com.tw/']
def parse(self, response):
post_urls = response.xpath(
"//a[@class='hero_menu_link']/@href").getall()
for post_url in post_urls:
yield scrapy.Request(post_url, self.parse_content)其中Request方法(Method)的第一個參數,就是「請求網址」,也就是熱門文章的下一層網頁網址,而第二個參數就是請求該網址後,所要執行的方法(Method),而parse_content則是筆者自訂的方法名稱,所以接下來就需要進行方法的定義,如下範例:
import scrapy
class HotNewsSpider(scrapy.Spider):
name = 'hot_news'
allowed_domains = ['www.inside.com.tw']
start_urls = ['http://www.inside.com.tw/']
def parse(self, response):
post_urls = response.xpath(
"//a[@class='hero_menu_link']/@href").getall()
for post_url in post_urls:
yield scrapy.Request(post_url, self.parse_content)
def parse_content(self, response):
pass而parse_content()方法(Method)中,就是來爬取熱門文章的下一層網頁內容,以本文為例就是包含「文章標題」及「文章摘要」,如下圖:

在文章標題的地方點擊滑鼠右鍵,選擇「檢查」,可以看到HTML原始碼如下圖:
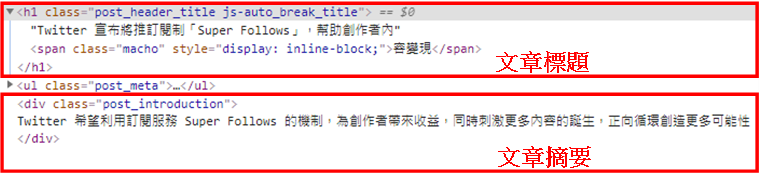
接著,就可以在parse_content()方法(Method)中,同樣使用Scrapy框架的xpath()方法(Method),來爬取「文章標題」及「文章摘要」,如下範例:
import scrapy
class HotNewsSpider(scrapy.Spider):
name = 'hot_news'
allowed_domains = ['www.inside.com.tw']
start_urls = ['http://www.inside.com.tw/']
def parse(self, response):
post_urls = response.xpath(
"//a[@class='hero_menu_link']/@href").getall()
for post_url in post_urls:
yield scrapy.Request(post_url, self.parse_content)
def parse_content(self, response):
# 熱門文章標題
hot_news_title = response.xpath(
"//h1[@class='post_header_title js-auto_break_title']/text()").get()
# 熱門文章摘要
hot_news_intro = response.xpath(
"//div[@class='post_introduction']/text()").get()
print(f"熱門文章標題:{hot_news_title},\n熱門文章摘要:{hot_news_intro}")利用以下的指令執行Scrapy網頁爬蟲:
$ scrapy crawl hot_news
截取部分執行結果如下圖:
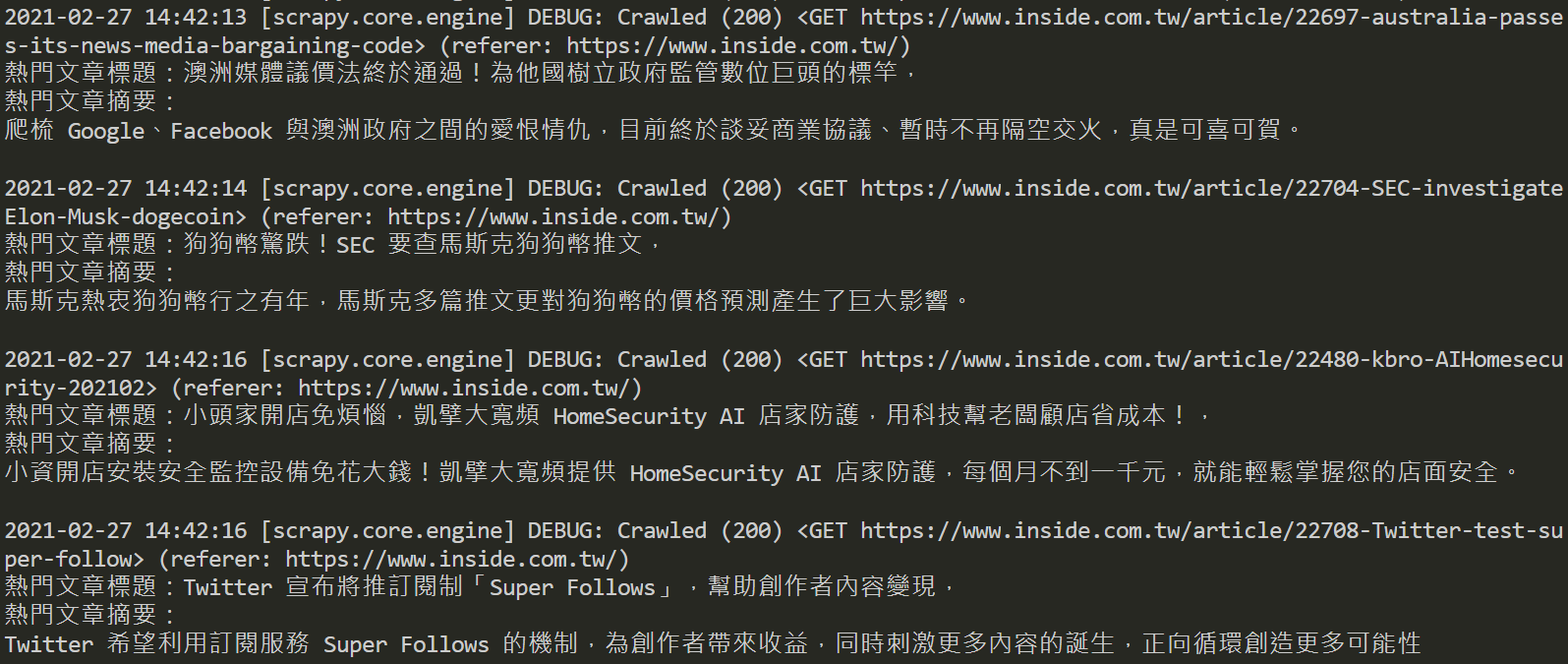
三、Scrapy框架建立資料模型封裝資料
在Scrapy網頁爬蟲取得資料後,為了能夠進行後續的處理,像是存入資料庫、匯出檔案或郵寄資料等,就需要將資料封裝在Scrapy的資料模型(ITEM),傳遞給資料模型管道(ITEM PIPELINE)來進行處理。
所以,開啟資料模型檔案(items.py),自行命名一個HotNewsItem類別(Class),並且定義兩個屬性欄位,分別為「文章標題」及「文章摘要」,如下範例:
class HotNewsItem(scrapy.Item):
hot_news_title = scrapy.Field() #熱門文章標題
hot_news_intro = scrapy.Field() #熱門文章摘要完成後,開啟Scrapy網頁爬蟲檔案(hot_news.py),在parse_content()方法(Method)中,建立Scrapy資料模型(HotNewsItem),並且分別指定爬取到的欄位值,如下範例第27~32行:
import scrapy
class HotNewsSpider(scrapy.Spider):
name = 'hot_news'
allowed_domains = ['www.inside.com.tw']
start_urls = ['http://www.inside.com.tw/']
def parse(self, response):
post_urls = response.xpath(
"//a[@class='hero_menu_link']/@href").getall()
for post_url in post_urls:
yield scrapy.Request(post_url, self.parse_content)
def parse_content(self, response):
# 熱門文章標題
hot_news_title = response.xpath(
"//h1[@class='post_header_title js-auto_break_title']/text()").get()
# 熱門文章摘要
hot_news_intro = response.xpath(
"//div[@class='post_introduction']/text()").get()
HotNewsItem = {
"hot_news_title": hot_news_title,
"hot_news_intro": hot_news_intro
}
return HotNewsItem截取部分執行結果如下圖:

從中可以看到,每筆資料皆被封裝到Scrapy的資料模型(ITEM)中,接下來,就能夠在資料模型管道(ITEM PIPELINE)做後續的資料處理了。
四、小結
本文利用簡單的範例,讓大家瞭解如果想要更進一步爬取下一層的網頁資料,則可以在Scrapy框架中先爬取所有下一層網頁的連結,接著透過Request()方法(Method)非同步的發送請求,最後即能自訂方法(Method)來爬取所需的下一層網頁資料。希望本文的實作教學有幫助到大家,如果有更好的技巧或想法,歡迎在底下留言和我分享唷。
如果您喜歡我的文章,請幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
- [Scrapy教學1]快速入門Scrapy框架的5個執行模組及架構
- [Scrapy教學2]實用的Scrapy框架安裝指南,開始你的第一個專案
- [Scrapy教學3]如何有效利用Scrapy框架建立網頁爬蟲看這篇就懂
- [Scrapy教學4]掌握Scrapy框架重要的CSS定位元素方法
- [Scrapy教學5]掌握Scrapy框架重要的XPath定位元素方法
- [Scrapy教學6]解析如何在Scrapy框架存入資料到MySQL教學
- [Scrapy教學7]教你Scrapy框架匯出CSV檔案方法提升資料處理效率
- [Scrapy教學8]詳解Scrapy框架爬取分頁資料的實用技巧
- [Scrapy教學9]一定要懂的Scrapy框架結合Gmail寄送爬取資料附件秘訣




如果我在第一層的地方也又資料想要爬取,我改怎麼做可以讓第一層的資料跟後面的資料綁再一起,像是我想要把第一層的網址給記錄下來。
回覆刪除