
在開發網頁爬蟲的過程中,是不是會擔心被偵測或封鎖,而爬不到所需的資料呢?
有些大型網站為了保護網頁上的資料不被大量的爬取,會特別偵測像Python網頁爬蟲這種非人工的自動化請求,這時候Python網頁爬蟲使用相同的IP來發送請求就很容易被發現。
所以,如果有多組IP能夠讓Python網頁爬蟲在發送請求時輪流使用,就能夠大幅降低被偵測的風險。而現在有許多網站上也有提供免費的Proxy IP,本文就以Free Proxy List網站為例,透過Python網頁爬蟲來蒐集上面的Proxy IP,製作我們的IP清單。實作步驟包含:
- Python爬取免費的Proxy IP
- Python驗證爬取的Proxy IP
- Python寫入爬取的Proxy IP到檔案
一、Python爬取免費的Proxy IP
首先,前往Free Proxy List網站,往下可以看到多組免費的Proxy IP,如下圖:
假設我們想要蒐集SSL Proxy IP,就可以在上方選單的地方選擇SSL Proxy,如下圖:

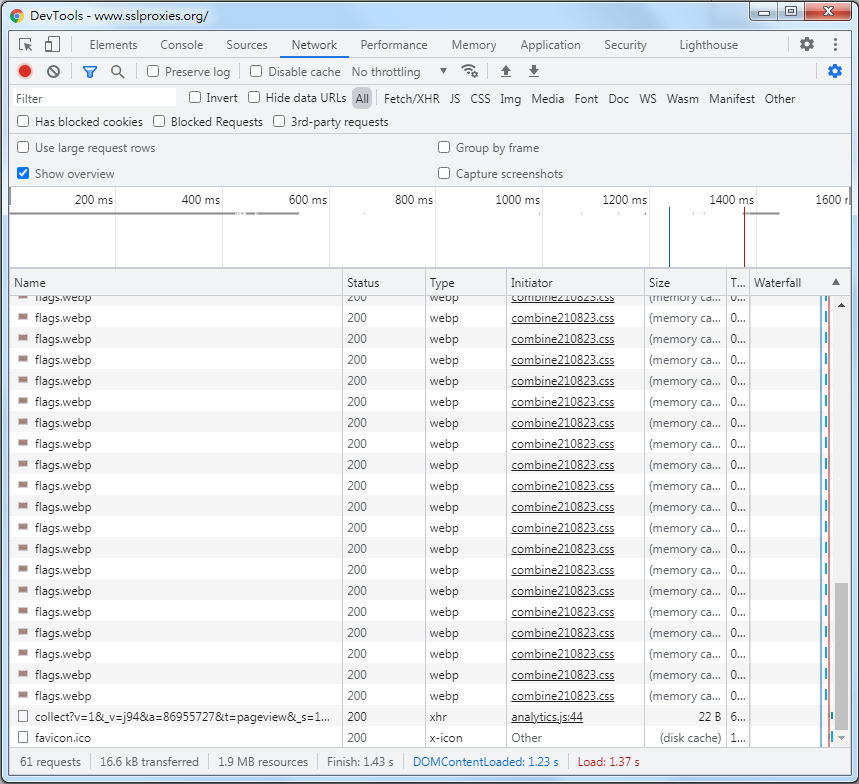
而想要利用Python網頁爬蟲爬取圖中的「IP Address(位址)」及「Port(埠號)」,可以點擊滑鼠右鍵,選擇「檢查」,切換到「Network(網路)」頁籤,並且按下Ctrl + R重新整理網頁,來觀察網頁背後的請求狀況,如下圖:
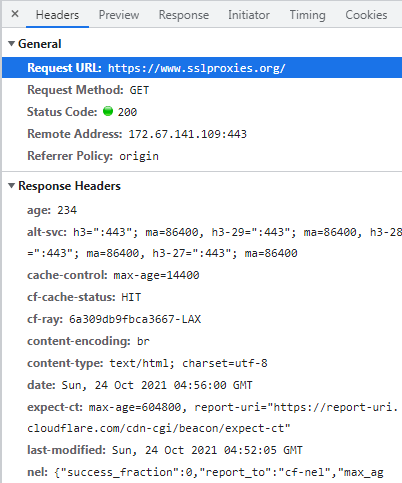
在搜尋的地方,隨意輸入一組SSL Proxy IP,就能夠搜尋到包含此SSL Proxy IP的請求,如下圖:

從Response(回應)頁籤可以看到,這個請求的回應結果包含了網頁畫面上的所有SSL Proxy IP,而要知道請求的網址,就要切換到Headers頁籤來查看Request URL(請求網址),如下圖:
接下來,Python網頁爬蟲就能夠透過此網址來進行SSL Proxy IP的爬取,如下範例:
import requests
import re
response = requests.get("https://www.sslproxies.org/")
print(response.text)從執行結果可以看到,其中還包含了一些HTML標籤及CSS樣式類別等,這時候,就能夠引用re(正規表達式)模組(Module),透過定義規則(Rule)來爬取SSL Proxy IP,如下圖:
import requests
import re
response = requests.get("https://www.sslproxies.org/")
proxy_ips = re.findall('\d+\.\d+\.\d+\.\d+:\d+', response.text) #「\d+」代表數字一個位數以上
print(proxy_ips)執行結果:
['171.233.151.214:55443', '13.229.73.17:443', '3.1.100.179:443', '177.32.243.159:3128', '185.51.10.19:80', '23.226.68.156:80', '52.185.165.115:8000', '202.57.35.74:38629', '3.140.109.255:80', '175.41.153.11:443', '194.233.69.41:443', '103.162.205.102:8181', '37.112.211.235:55443', '110.74.222.71:44970', ...]
二、Python驗證爬取的Proxy IP
雖然Python網頁爬蟲爬取到了網頁畫面上的SSL Proxy IP,但是未必每一組都有效,所以,可以透過像SeeIP或ipify網站來進行驗證,如下範例:
import requests
import re
response = requests.get("https://www.sslproxies.org/")
proxy_ips = re.findall('\d+\.\d+\.\d+\.\d+:\d+', response.text) #「\d+」代表數字一個位數以上
valid_ips = []
for ip in proxy_ips:
try:
result = requests.get('https://ip.seeip.org/jsonip?',
proxies={'http': ip, 'https': ip},
timeout=5)
print(result.json())
valid_ips.append(ip)
except:
print(f"{ip} invalid")截取部分執行結果
以上範例只要Python網頁爬蟲所爬取的SSL Proxy IP有效,就把它加入到valid_ips串列(List)中,無效則顯示invalid。
當然,如果不想要驗證那麼多組SSL Proxy IP,可以利用Python的enumerate()函式(Function)取得迴圈的索引值,來指定所要驗證的SSL Proxy IP組數,如下範例第12行:
import requests
import re
response = requests.get("https://www.sslproxies.org/")
proxy_ips = re.findall('\d+\.\d+\.\d+\.\d+:\d+', response.text) #「\d+」代表數字一個位數以上
valid_ips = []
for index, ip in enumerate(proxy_ips):
try:
if index <= 30: #驗證30組IP
result = requests.get('https://ip.seeip.org/jsonip?',
proxies={'http': ip, 'https': ip},
timeout=5)
print(result.json())
valid_ips.append(ip)
except:
print(f"{ip} invalid")三、Python寫入爬取的Proxy IP到檔案
驗證完成並且得到有效的SSL Proxy IP串列(List)後,就可以透過迴圈將串列(List)中的SSL Proxy IP寫入到檔案中,讓後續能夠進行運用,如下範例:
import requests
import re
response = requests.get("https://www.sslproxies.org/")
proxy_ips = re.findall('\d+\.\d+\.\d+\.\d+:\d+', response.text) #「\d+」代表數字一個位數以上
valid_ips = []
for ip in proxy_ips:
try:
result = requests.get('https://ip.seeip.org/jsonip?',
proxies={'http': ip, 'https': ip},
timeout=5)
print(result.json())
valid_ips.append(ip)
except:
print(f"{ip} invalid")
with open('proxy_list.txt', 'w') as file:
for ip in valid_ips:
file.write(ip + '\n')
file.close()執行結果

四、小結
本文使用了Python網頁爬蟲蒐集網頁上的免費Proxy IP,並且透過開源的平台進行驗證後,寫入到檔案。有了多組的Proxy IP,在開發Python網頁爬蟲專案時,就能夠利用不同的Proxy IP來發送請求,降低被網站偵測或封鎖的風險。在下一篇文章,就來使用本文所蒐集的免費Proxy IP,爬取網站資料。
大家在開發Python網頁爬蟲專案時,如果有其它不錯的降低偵測或封鎖方法,歡迎在底下留言和我分享唷~
如果您喜歡我的文章,別忘了在下面訂閱本網站,以及幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。




留言
張貼留言