
本文以Kaggle網站的Amazon 2009-2019年Top50暢銷書資料集(bestsellers with categories.csv)為例,教大家如何查找及清理資料集的重複資料,提升資料的品質。重點包含:
- Pandas duplicated()查找重複資料
- Pandas drop_duplicates()刪除重複資料
- Pandas groupby()、agg()群組重複資料
一、Pandas duplicated()查找重複資料
import pandas as pd
df = pd.read_csv('bestsellers with categories.csv')
print(df)執行結果
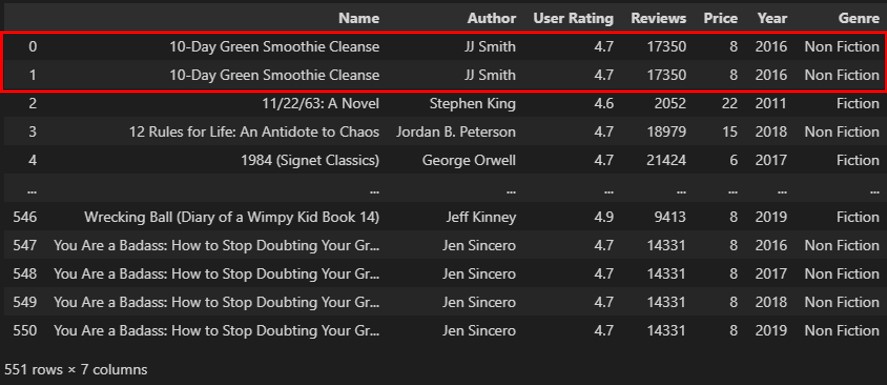
import pandas as pd
df = pd.read_csv('bestsellers with categories.csv')
print(df.duplicated())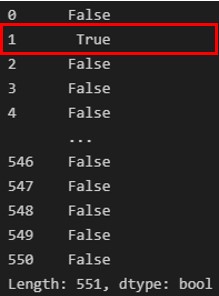
import pandas as pd
df = pd.read_csv('bestsellers with categories.csv')
print(df[df.duplicated()])
- subset-查找特定欄位的重複資料
- keep-保留第一筆(first)、最後一筆(last)或全部(False)的重複資料
import pandas as pd
df = pd.read_csv('bestsellers with categories.csv')
column_names = ['Name', 'Author', 'Year', 'Genre']
df = df[df.duplicated(subset=column_names, keep=False)]
print(df)
二、Pandas drop_duplicates()刪除重複資料
而要刪除完全一樣的重複資料,可以利用Pandas套件的drop_duplicates()方法(Method),如下範例:
import pandas as pd
df = pd.read_csv('bestsellers with categories.csv')
df.drop_duplicates(inplace=True)其中,inplace關鍵字參數代表直接從現有資料集中刪除重複資料。
另外,要刪除特定欄位重複的資料,同樣可以透過subset及keep關鍵字參數來達成,如下範例:
import pandas as pd
df = pd.read_csv('bestsellers with categories.csv')
column_names = ['Name', 'Author', 'Year', 'Genre']
df.drop_duplicates(subset=column_names, keep='first', inplace=True)以上則是將Name(書名)、Author(作者)、Year(出版年)及Genre(類型)四個欄位重複的資料進行刪除,並且保留重複資料的第一筆。
三、Pandas groupby()、agg()群組重複資料
在上面的範例中,我們找到了Name(書名)、Author(作者)、Year(出版年)及Genre(類型)四個欄位都一樣的重複資料,剩下的User Rating(使用者評價)、Reviews(評論數)及Price(價格)三個欄位資料假設會隨著時間而變動。
這時候,就可以利用Pandas套件的groupby()方法(Method)群組相同資料的欄位,以及agg()方法(Method),統計運算剩餘的不同資料欄位,達到合併重複資料成一筆的效果,如下範例:
import pandas as pd
df = pd.read_csv('bestsellers with categories.csv')
column_names = ['Name', 'Author', 'Year', 'Genre']
summeries = {'User Rating': 'mean', 'Reviews': 'sum', 'Price': 'mean'}
df = df.groupby(by=column_names).agg(summeries).reset_index()
print(df)執行結果

四、小結
本文是筆者Mike在DataCamp平台上所學到的Pandas套件資料清理技巧,加以應用和大家分享。DataCamp平台上有非常多與資料科學、分析有關的教學,包含資料視覺化、清理、機器學習等,並且有專家帶領你完成資料分析專案,大家有興趣的話,可以加入DataCamp平台一起學習唷。
如果喜歡我的文章,別忘了在下面訂閱本網站,以及幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
- [Pandas教學]善用Pandas套件幫你清理資料範圍異常的資料
- [Pandas教學]教你用Pandas套件清理資料中的常見資料型態問題
- [Pandas教學]使用Pandas套件將資料集拆分成多個CSV檔案資料應用
- [Pandas教學]3個Pandas套件比較CSV檔案資料之間的差異秘訣
- [Pandas教學]利用Pandas套件的to_html方法在網頁快速顯示資料分析結果
- [Pandas教學]4個必學的Pandas套件處理遺漏值(Missing Value)資料方法
- [Pandas教學]有效利用Pandas套件的pipe方法打造資料處理流程管道
- [Pandas教學]3個優化Pandas套件讀取大型CSV檔案資料的技巧
- [Pandas教學]一定要學會的Pandas套件讀寫Google Sheets試算表資料秘訣
- [Pandas教學]客製化Pandas DataFrame樣式提升資料可讀性的實用方法
- [Pandas教學]3個Pandas套件合併多個CSV檔案資料的實用技巧
- Pandas教學]看完這篇就懂Pandas套件如何即時讀取API的回應資料
- [Pandas教學]快速掌握Pandas套件讀寫SQLite資料庫的重要方法
- [Pandas教學]輕鬆入門3個常見的Pandas套件排序資料方式
- [Pandas教學]有效利用Pandas套件篩選資料的應用技巧
- [Pandas教學]善用Pandas套件的Groupby與Aggregate方法提升資料解讀效率
- [Pandas教學]使用Pandas套件實作資料清理的必備觀念(上)
- [Pandas教學]使用Pandas套件實作資料清理的必備觀念(下)
- Visual Studio Code漂亮印出Pandas DataFrame資料的實用方法
- [Pandas教學]資料視覺化必懂的Pandas套件繪製Matplotlib分析圖表實戰
- [Pandas教學]5個實用的Pandas讀取Excel檔案資料技巧
- 解析Python網頁爬蟲如何有效整合Pandas套件提升資料處理效率
- [Pandas教學]掌握Pandas DataFrame讀取網頁表格的實作技巧
- [Pandas教學]資料分析必懂的Pandas DataFrame處理雙維度資料方法
- [Pandas教學]資料分析必懂的Pandas Series處理單維度資料方法




留言
張貼留言