
而在蒐集資料或人為處理資料的過程中,就有可能發生資料超出所要分析的範圍錯誤,導致分析結果出現異常。本文將以Kaggle網站的Kindle Store電子書店評論資料集(kindle_reviews.csv)為例,來和大家分享如何利用Pandas套件來處理以下兩種類型的資料範圍錯誤:
- Pandas數字範圍處理
- Pandas日期範圍處理
一、Pandas數字範圍處理
首先,利用Pandas套件讀取資料集,如下範例:
import pandas as pd
df = pd.read_csv('kindle_reviews.csv')
df執行結果

假設我們只想要分析「overall評價欄位」1~4分的書籍,這時候,評價為5的書籍資料就超出了分析需求範圍,如果沒有進行處理,就會讓分析結果失去準確性。
而想要利用Pandas套件處理數字範圍的資料,有以下兩種常見的方式:
- 刪除資料
通常會建議超過範圍資料的占比較小時,才考慮透過刪除的方式,否則,超過範圍資料的占比過大,刪除可能造成重要資料訊息的遺失。
而Pandas套件刪除資料的方式分為兩種,可以是選擇所需的範圍資料,如下範例:
import pandas as pd
df = pd.read_csv('kindle_reviews.csv')
df = df[df['overall'] <= 4]或將超過範圍的資料刪除,如下範例:
import pandas as pd
df = pd.read_csv('kindle_reviews.csv')
df.drop(df[df['overall'] > 4].index, inplace=True)執行結果
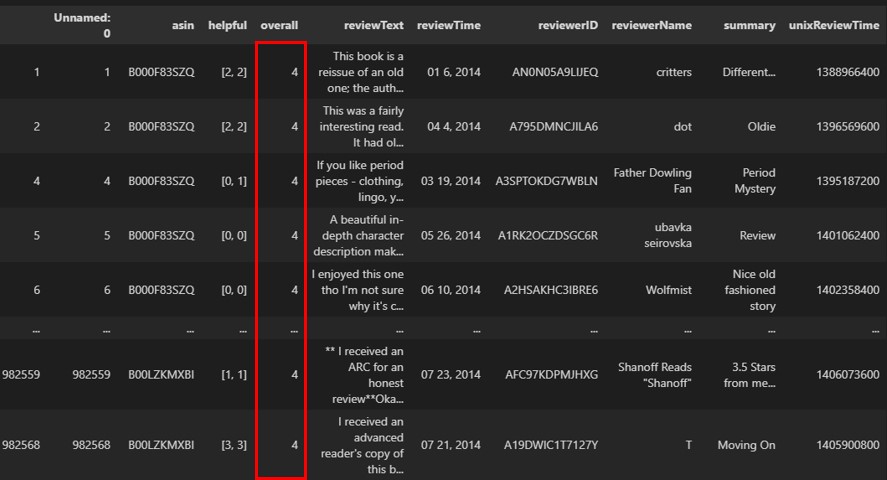
可以透過assert陳述式來進行欄位資料範圍的驗證,如下範例:
assert df['overall'].max() <= 4
PS.沒有顯示訊息代表驗證通過
- 依據商業假設設定自訂值
如果不想刪除超過範圍的資料,可以依據商業假設,將超過範圍的資料,利用Pandas套件自訂為符合範圍的值。舉例來說,將評價為5的書籍資料修改為4,如下範例:
import pandas as pd
df = pd.read_csv('kindle_reviews.csv')
df.loc[df['overall'] > 4, 'overall'] = 4執行結果
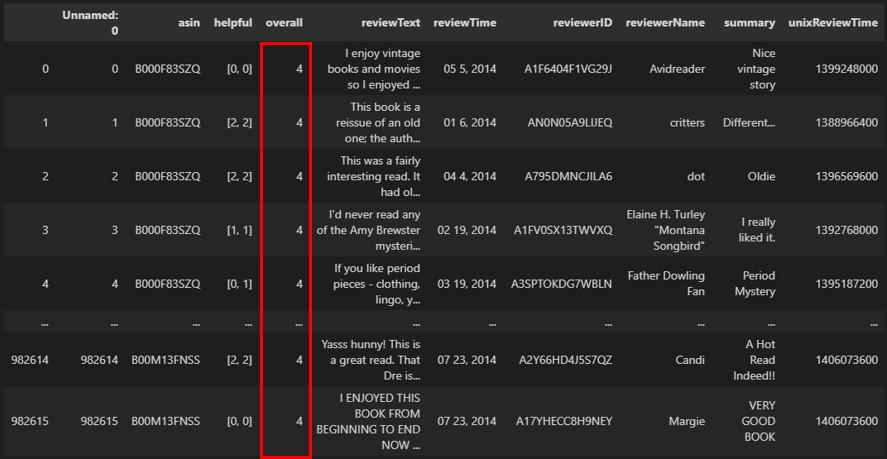
同樣,利用assert陳述式來進行驗證,如下範例:
assert df['overall'].max() <= 4
二、Pandas日期範圍處理
另一個常見的資料範圍錯誤,就是日期資料,像是含有未來日期的資料等。
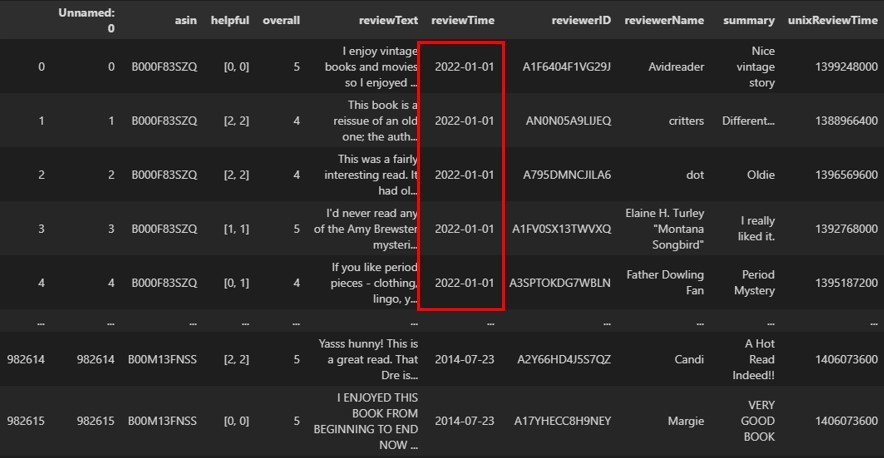
假設,Kindle Store電子書店評論資料集(kindle_reviews.csv)的「ReviewTime評論日期欄位」含有未來日期,如下範例:
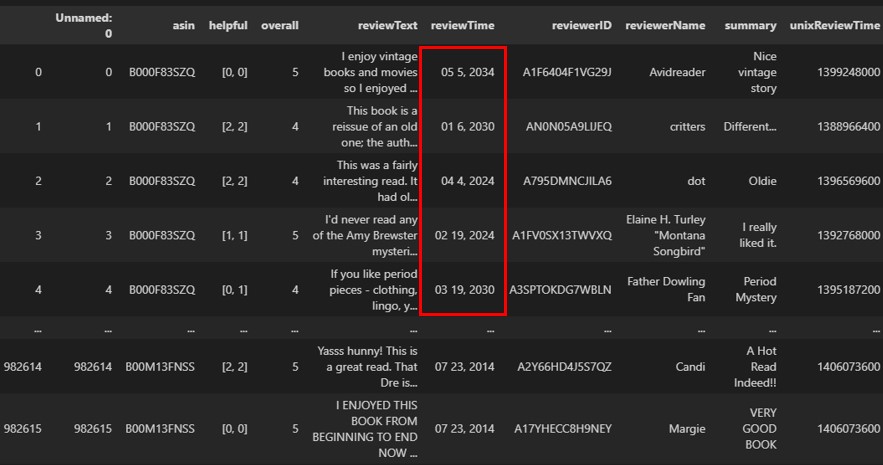
而這對於分析人員來說,就會是髒資料(Dirty Data)或沒有意義。
要利用Pandas套件處理日期範圍錯誤的資料,可以先將欄位資料型態轉型為日期,方便之後的日期資料操作,如下範例:
import pandas as pd
df = pd.read_csv('kindle_reviews.csv')
df['reviewTime'] = pd.to_datetime(df['reviewTime'])
print(df)執行結果
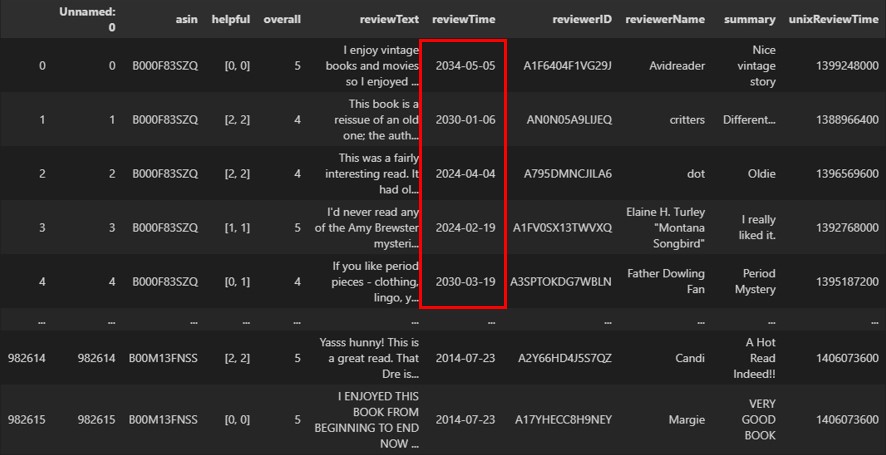
接著,同樣可以使用下兩種解決方法:
- 刪除資料
引用datetime模組(Module),來取得目前的日期,如下範例:
import pandas as pd
import datetime
df = pd.read_csv('kindle_reviews.csv')
df['reviewTime'] = pd.to_datetime(df['reviewTime'])
today = datetime.date.today()這時候,就可以使用Pandas套件,利用目前的日期來選擇有效的「ReviewTime評論日期欄位」資料,如下範例:
import pandas as pd
import datetime
df = pd.read_csv('kindle_reviews.csv')
df['reviewTime'] = pd.to_datetime(df['reviewTime'])
today = datetime.date.today()
df = df[df['reviewTime'].dt.date <= today]或是刪除「ReviewTime評論日期欄位」中含有未來日期的資料,如下範例:
import pandas as pd
import datetime
df = pd.read_csv('kindle_reviews.csv')
df['reviewTime'] = pd.to_datetime(df['reviewTime'])
today = datetime.date.today()
df.drop(df[df['reviewTime'].dt.date > today].index, inplace=True)
執行結果
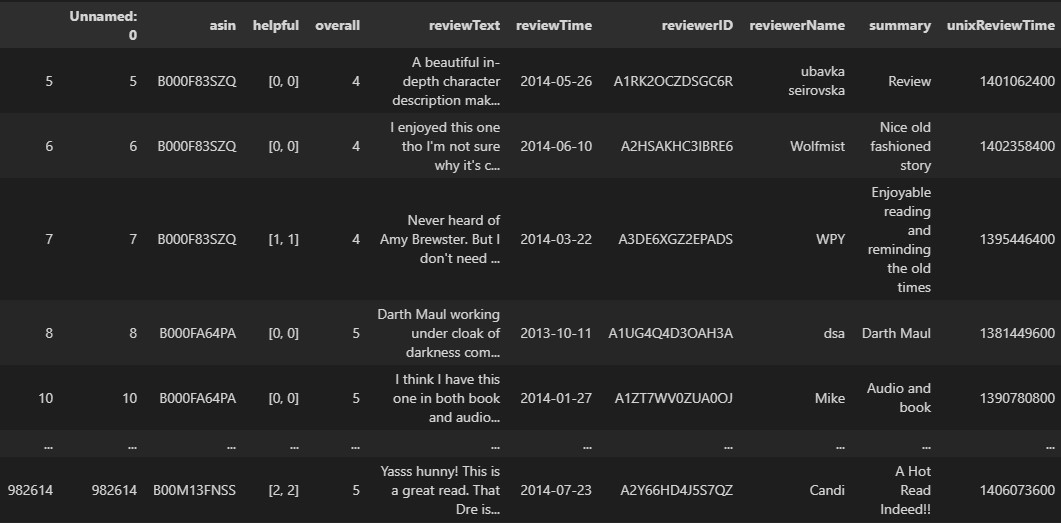
刪除後,利用assert陳述式來驗證「ReviewTime評論日期欄位」不含未來日期的資料,如下範例:
assert df.reviewTime.max().date() <= today
- 依據商業假設設定自訂值
依據所需的商業假設,使用Pandas套件將「ReviewTime評論日期欄位」中含有未來日期的資料,替換成目前的日期時間,如下範例:
import pandas as pd
import datetime
df = pd.read_csv('kindlSe_reviews.csv')
df['reviewTime'] = pd.to_datetime(df['reviewTime'])
today = datetime.datetime.today()
df.loc[df['reviewTime'].dt.date > today, 'reviewTime'] = pd.to_datetime(today)
print(df)執行結果
最後,利用assert陳述式驗證「ReviewTime評論日期欄位」不含未來日期的資料,如下範例:
assert df.reviewTime.max().date() <= today
三、小結
在使用Pandas實作資料分析的過程中,可能依據不同的需求來使用資料,所以在進行分析時,對於要處理的「資料範圍」就需要謹慎的加以處理,像是利用本文舉例的刪除或替代成自訂值的方式加以解決,否則在分析結果或報表上,就會顯示不合邏輯的髒資料(Dirty Data),導致失去參考價值。
本文是筆者Mike在DataCamp平台上所學到的Pandas套件資料清理技巧,加以應用和大家分享。DataCamp平台上有非常多與資料科學、分析有關的教學,包含資料視覺化、清理、機器學習等,並且有專家帶領你完成資料分析專案,大家有興趣的話,可以加入DataCamp平台一起學習唷。
如果喜歡我的文章,別忘了在下面訂閱本網站,以及幫我按五下Like(使用Google或Facebook帳號免費註冊),支持我創作教學文章,回饋由LikeCoin基金會出資,完全不會花到錢,感謝大家。
- [Pandas教學]教你用Pandas套件清理資料中的常見資料型態問題
- [Pandas教學]使用Pandas套件將資料集拆分成多個CSV檔案資料應用
- [Pandas教學]3個Pandas套件比較CSV檔案資料之間的差異秘訣
- [Pandas教學]利用Pandas套件的to_html方法在網頁快速顯示資料分析結果
- [Pandas教學]4個必學的Pandas套件處理遺漏值(Missing Value)資料方法
- [Pandas教學]有效利用Pandas套件的pipe方法打造資料處理流程管道
- [Pandas教學]3個優化Pandas套件讀取大型CSV檔案資料的技巧
- [Pandas教學]一定要學會的Pandas套件讀寫Google Sheets試算表資料秘訣
- [Pandas教學]客製化Pandas DataFrame樣式提升資料可讀性的實用方法
- [Pandas教學]3個Pandas套件合併多個CSV檔案資料的實用技巧
- Pandas教學]看完這篇就懂Pandas套件如何即時讀取API的回應資料
- [Pandas教學]快速掌握Pandas套件讀寫SQLite資料庫的重要方法
- [Pandas教學]輕鬆入門3個常見的Pandas套件排序資料方式
- [Pandas教學]有效利用Pandas套件篩選資料的應用技巧
- [Pandas教學]善用Pandas套件的Groupby與Aggregate方法提升資料解讀效率
- [Pandas教學]使用Pandas套件實作資料清理的必備觀念(上)
- [Pandas教學]使用Pandas套件實作資料清理的必備觀念(下)
- Visual Studio Code漂亮印出Pandas DataFrame資料的實用方法
- [Pandas教學]資料視覺化必懂的Pandas套件繪製Matplotlib分析圖表實戰
- [Pandas教學]5個實用的Pandas讀取Excel檔案資料技巧
- 解析Python網頁爬蟲如何有效整合Pandas套件提升資料處理效率
- [Pandas教學]掌握Pandas DataFrame讀取網頁表格的實作技巧
- [Pandas教學]資料分析必懂的Pandas DataFrame處理雙維度資料方法
- [Pandas教學]資料分析必懂的Pandas Series處理單維度資料方法




留言
張貼留言